The naive approach to render volumetric scenes(The reality behind Gaussian Splatting and NERFS)
The ability to capture reality is a very important part of storytelling
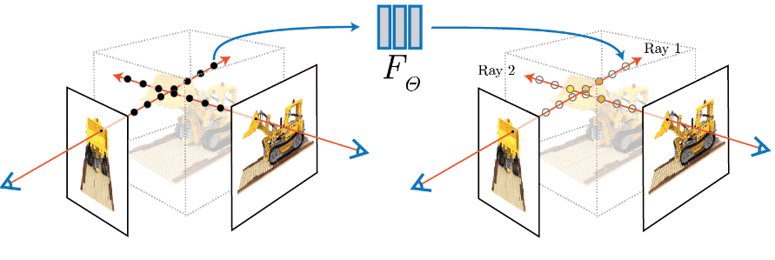
In 2020 a new 3D capture system that required lots and lots of calibrated images but that provided very good results to generate 3D data was created, it was called neural radiant fields(NERF).
This 3d capture method takes all the images and using volumetric rendering it generates a 3D volume. It uses neural networks to facilitate determining the colour that should be given to each voxel
Its objective is to reconstruct all the volume space colours from the images rays to eventually get the 3D reconstruction.
Nerf Timeline
Since the creation of nerf then there has been an explosion in the field, here are some important events:
2020 – Nerf was released and it was taking a very long time to render.
2021 – Thanks to real time rendering, new approaches to render faster appeared(PlenOcTrees and FastNerf)
2022 – Faster training methods appeared(Plenoxels, Instance-NGP)
2023 – 3D generative models were able to create from text inputs 3D shapes(DreamFUsion)
2023-2024 – Gaussian splatting was created, providing better quality and speed.
The Naive Approach to edit volumetric scenes.
What if we want to make further modifications to the scene created by nerf? What if we have a city scene in summer but we want to make it look in winter full of snow? Or we have a 3D scan of a person and we would like to make the person look older?
The common naive approach to apply modifications to the results of nerf and gaussian splatting has been to generate a 3D mesh from the volume and edit that mesh.
But recent research has been done to apply, based on text, modifications to those voxels, which could bring better results than applying the changes to the actual 3D meshes. Training the machine learning model to apply those changes in the volume allows us to really refine the activation to a specific reign, improving the final result.
This becomes very interesting for visual effect studios allowing them to easily customise nerf results but it can be used in other industries as well. It can let robots have semantics in how to interact with the world. For instance, know what shoe type to take from a shoe storage.


Returning to visual effects realm, edit directly the volume can help get smooth scenes, once a shot is recorded it may have some unwanted camera movement, but using nerf and gaussian splating you can render a new path from the scene so it does not matter if the initial camera recording was smooth or not, a new path can be made afterwards.
What is missing?
We are in need of multimodal systems that allow us to interact with other elements of the scene, like sound or movement, in a synergetic way. Most recent papers are aiming to tackle static 3D worlds, but the world is 4D, there is movement. Some initiatives to Reconstruct and track humans from videos are starting to appear. Wonder Ai is decoupling humans and camera motion from videos which is very cool, but still, work is required in the field.
Another major problem to tackle will be that there are not that many 3D datasets and those algorithms need huge data sets to be trained. That is going to make more research towards synthetic 3D scenes creation in next years.
Enjoy the rest of your day.
Oriol